Dismantling pseudo-skepticism
How skeptics like Michael Shermer get it wrong

In this age of misinformation skepticism is essential to distinguish what is true, and plenty have taken upon themselves the noble cause of dispelling misinformation in order to guide the public to the correct truth. The problem is that these self-proclaimed fact-checkers still commit errors in reasoning, more than enough to doubt their conclusions. So it’s not unreasonable to doubt the skeptics.
But who doubts the skeptics? Clearly the lunatic conspiracy theorists—of which there’s many, no doubt—but not all who doubt the skeptics are lunatic conspiracy theorists. To think “if you doubt the skeptics, you are a lunatic” is a classic converse error fallacy.
How do the skeptics demarcate between lunatics and valid doubt? The short answer is that they don’t. There’s so much misinformation and bad arguments out there that people who try to debunk misinformation are simply overwhelmed by the sheer volume of it and constantly dismiss valid doubt. We can see how they failed at important stories of our time, like the COVID-19 lab leak theory in which the people who doubted the official natural zoonotic transmission theory turned out to be right.
The big wrench thrown in the system of logic is the human need to know things. Every time we are presented with a question we immediately want to know the answer: is it true? If we cannot see how something could be true, then we automatically assume it’s false, and that works most of the time… except when it doesn’t.
What else could we do? The nature of knowledge is such that we cannot know everything, all we can do is try our best guess, and sometimes we will believe true things are false, and false things are true. Epistemology is not that simple.
But actually, it is simple. All we have to do is resist our natural urge, and go for the third option most people don’t even realize it’s there: unbelief. When the answer is not known to be true, you don’t have to assume it’s false: just don’t believe anything. It’s OK to say “I don’t know”. For a deeper exploration in this concept read my other article: First principles of logic.
We have an urge to know if Rick Deckard was a replicant or not, but the rational position is the default position: unknown, uncertain, unbelief.
Given that in any moment in time we have incomplete information for most questions, it would not have been reasonable to conclude that the COVID-19 lab leak theory was true in 2020, so when the established skeptics criticized the gullible people for believing this theory on the basis that “there’s no evidence for it”, they were right. But that doesn’t mean it was necessarily false either.
Once again we stumble upon the the converse error fallacy: if the theory was true we would expect to see evidence for it, but the fact that we don’t see evidence for it doesn’t necessarily mean that the theory is not true. Or: absence of evidence is not proof of absence.
A true skeptic is someone who doubts, not someone who negates. The people who claimed that the lab leak theory was false on the basis of lack of evidence were not skeptics, they were pseudo-skeptics. A true skeptic is someone who not only doubted the gullible “lunatics” claiming it was true, but also the pseudo-skeptic “rationalists” claiming it was false. It’s not easy to be in this fringe position, especially when both sides pressure you to commit to their position, or attack you for seemingly be in the enemy’s position. I’m going to call these skeptics “meta-skeptics”, to distinguish them from the pseudo-skeptics, but in truth they should just be called “skeptics”.
A meta-skeptic is someone like Bret Weinstein who in the absence of substantive evidence doesn’t commit to a position, thus not only avoiding type I errors (false-positives), but also type II errors (false-negatives). A pseudo-skeptic is someone like Michael Shermer who is prone to make type II errors.
To be fair, Michael Shermer does avoid many type II errors, he is more skeptical than most, and thus most of the time he gets most questions right, including the lab leak theory question. But many times he doesn’t.
The quintessential difference between the meta-skeptics and the pseudo-skeptics is the doubt in their own certainty. In other words: a meta-skeptic doubts their own skepticism.
To show the difference in a real world argument, I’m first going to dig deep into a problem in probability that most people get wrong (as they do in many problems in probability and statistics), but the true answer is mathematically correct beyond any reasonable doubt.
Likelihood doesn’t mean what you think it means
The problem is simple: a coin is tossed 10 times, 8 of those times it landed heads, what’s the probability that the next toss will land heads?
Before exploring the answer, it’s worth noting that it’s related to the meaning of probability, likelihood, and statistics. It may sound trivial, but the philosophical underpinnings of probability is actually a deep debate, and the foundations of probability—explored in probability theory—are much more complex than most people realize. The answer to the question “what is probability?” is anything but simple.
But let’s not start on the deep end. At first glance the chances seem to be on the side of heads, a gullible person untrained in probability might say 80%, but as any rational person knows: we shouldn’t trust our first instinct.
Someone who has studied probability in university might know that the probability of independent events are not affected by previous events, therefore it’s irrelevant how many times it landed heads in the previous 10 tosses, the probability of the next toss remains the same. Therefore 50%.
Except I never claimed the coin was fair. A long-term probability of 50% heads was an unwarranted assumption.
This is where we start to see the demarcation of different levels of skepticism. The gullibles who answered 80% can be thought of as level-0 skeptics, and the pseudo-skeptics who answered 50% are level-1 skeptics. Nassim Taleb gives a similar example to show how the academics who ignore the evidence are actually not that smart, and calls them Intellectual Yet Idiots. They are so full of themselves that they don’t even consider the possibility that they could be wrong in such a simple question. In other words: they lack intellectual humility, they are not very skeptical of their own intellectual capabilities. Ironically the “dunce” who answered 80% is more right.
In their rush to answer the question, what the level-1 skeptics missed is the whole problem, which is: how do you determine the probability of a coin landing heads?
If a coin was fair, you would expect that in 100 tosses it would land heads around 50 times. But that’s if the coin was fair (p=0.5), which we don’t know a priori. If instead it lands heads 80 times, that’s a good indication that it isn’t fair, but it’s not impossible for a fair coin to do that, just very unlikely.
Welcome to the problem of the real world. In academia a professor would give you the probabilities of different events happening for you to apply neat formulas and theorems, but in the real world there’s no such thing: that’s precisely what you need to figure out.
So what would a level-2 skeptic do? First, we don’t assume anything, we suppose. If we suppose p=0.8, the probability that we observe the data is (10 choose 8) * 0.8^8 * 0.2^2, so around 30%, and if we suppose p=0.5, the probability is (10 choose 8) * 0.5^8 * 0.5^2, so around 4%. Clearly it’s more likely that p is 0.8, but it’s not a certainty.
The reality is that p could be anything: 0.4, 0.6, 0.9. We just don’t know. But what we can do is use the beta distribution to determine the relative likelihood of different probabilities, and this is the likelihood function of our problem (α=9, β=3):

Now we can visually see that both level-1 and level-0 skeptics are wrong, but one is more wrong than the other. We can also see what is most likely.
Moreover, the intuition that a rational person assumes what is most likely is clearly wrong, since other possibilities—although not as likely—are still very much likely. If you play Russian roulette, what is more probable is that you won’t lose, but should you assume that?
Is it likely that a fair coin would have landed heads 8 out of 10 times? No. But a rational person understands that unlikely events do happen, in fact, they happen all the time.
So, what is the level-2 answer to the question: what’s the probability that the next toss will land heads? Uncertain.
Compounding uncertainty
The coin toss example is extremely simple and yet most people get it wrong, things become increasingly complex when we are trying to figure out the behavior of the event itself. We know a coin toss follows a binomial distribution, but what happens if we don’t even know the distribution of the event?
In the real world all we have is the raw data and it’s up to us to figure out what it means. This example will map to a real world question, but to avoid bias I’m going to use an abstract c() function that ties directly to our previous example: if the function returns 8, that corresponds to p = 0.8. To have a sense of the behavior we run the function 1000 times and plot the histogram:
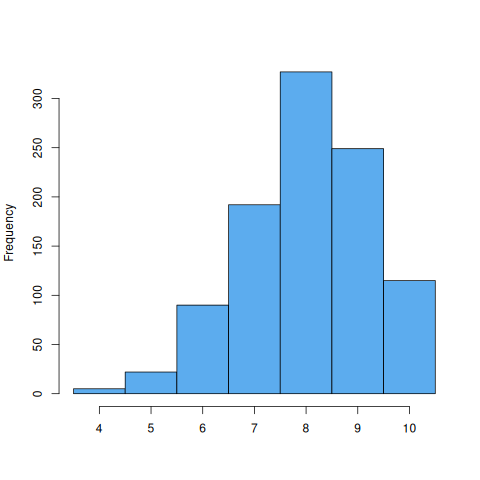
Except this is not the real function, this follows a binomial distribution, our function follows an unknown distribution:

Can you spot the difference?
One might be tempted to say the difference doesn’t really matter, what is clear is that p is usually above 0.5, and most likely to be 0.8 (although values like 0.4 can’t be rejected). That is true, but I didn’t mention something: the c() function has a threshold argument, and that plot is of the specific case of c(4). If we think of the threshold as 4 kg and 80% of the events fall below that, then surely by increasing it to 8 kg we should catch most of them:

Except we don’t. In some runs we still have only 60% below 8 kg. Let’s increase it to 20:

There’s still some runs with only 70%. It turns out that it doesn’t matter how much we increase the threshold, there will always be a chance that an event surpasses it, that’s because this is a heavy-tailed distribution, in particular it’s a Pareto distribution, and its variance is infinite.
It seems unintuitive to think that if 80% of events fall below 4 kg, there could be one above 1000 kg, but it totally could.
The probability distribution does matter.
So how does this map to the real world? If c() is a function that calculates the probability of conspiracy theories to be false, a result of 8 would mean 80% (most likely), and c(4) would be a conspiracy theory of complexity 4 (arbitrary unit). But as we saw in the graph, the same function could return a 3, meaning 30%.
If c(4) returns 80%, we would expect c(8) to return something way higher, maybe even 100%. That is: conspiracy theories twice as complex should be virtually non-existent. But that’s not what we see in the graphs, we see that c(4) and c(8) could totally return 80% both.
If you don’t quite get the significance of the above, don’t worry too much about it, the point is that 80% failure rate can mean something completely different than what most people intuit.
But wait…
If that wasn’t enough, in the real world we don’t even have something as clear-cut as true or false. As we saw in the first section, the conclusion could be uncertain. Because of the need to say something definitive many people conclude that a particular conspiracy theory is “unlikely to be true”.
So it’s not just a probability of an unknown probability of an unknown distribution, it’s a probability of an unknown probability of an unknown distribution of which the only data we have is a sample of probabilities.
Anyone who derives certainty from this is simply not being rational.
The claim
Finally we arrive at the claim I want to focus on:
“The grander the conspiracy theory, the less likely it is to be true."
Let’s tackle it from the bottom: the data. To figure out the likelihood (possible probability), we need some sample, let’s say 10 conspiracy theories. If we focus on conspiracy theory #1, it could be true, false, or uncertain. If it’s uncertain people are still going to try to conclude something, for example: “20% likely to be true”. This is of course subjective, two people could arrive to completely different probabilities. And even if we assume that 20% is the most objective logical conclusion, at the end of the day it’s either true or false, and could very well be true. So we have to cheat, we assume that a conspiracy theory with a probability less than 50% is false, otherwise it’s true. So conspiracy theory #1 is false. Then we have to do the same for all the other 9 conspiracy theories.
Say we found out that 8 conspiracy theories were “false”, and therefore 2 were “true”. Can we deduce the actual probability of all conspiracy theories based on this limited sample? No, we can’t. The likelihood is a function, even though the actual probability is most likely to be 20% true, it could very well be 50%. So we have to cheat again and assume that the actual probability is the most likely probability.
So we have now an actual probability of 20%, but this is of “typical” conspiracy theories, how do we extend that to “grand” conspiracies? To do that we need the meta-probability distribution of conspiracy theories. If the distribution is a heavy-tailed distribution, then all bets are off, because the probability of conspiracy theories of level 8 could be as likely as a sample of conspiracy theories of level 4. So we cheat again and assume the meta-probability distribution is Gaussian (not heavy-tailed), therefore conspiracy theories of level 8 would be significantly different.
Only after cheating four times can we arrive at the conclusion that grander conspiracy theories are less likely to be true (given the conspiracy theories we have analyzed so far).
But of course a meta-skeptic would not cheat, not even once. There is no need to make any assumptions, we don’t need to know a priori the likelihood of grand conspiracy theories, we can simply say: “we don’t know”. We can evaluate every conspiracy theory individually without prejudice based on size.
Maybe it’s true that the grander conspiracy theories are indeed less likely to be true, but we cannot be certain given the incomplete and fuzzy data.
And there’s no need to know anything about statistics or probability theory, we could simply ask Michael Shermer if he is absolutely certain his claim cannot possibly be false, if he answers “yes” then we know he is not a true skeptic, because a true skeptic would doubt not only his understanding of probability and statistics, but even his own certainty.
Ultimately the problem is not that Michael Shermer assumes the claim is true, the problem is that it’s part of his epistemological toolkit to evaluate other claims and negates them instead of merely doubting them. When Shermer encounters a new grand conspiracy theory, he is already biased: “grand conspiracy theories are unlikely to be true, don’t you know?”.
This is not the only error of Michael Shermer where his lack of doubt gets in the way, just the one that is easier to prove objectively. And of course many of the so called “skeptics” make similar mistakes exaggerating their own certainty.
Conclusion
A meta-skeptic should doubt everything: the probability of a coin landing heads, the likelihood given a sample, the characteristics of a probability distribution, even dogmatic claims such as: parallel lines don’t cross (lines with a common perpendicular can in fact intersect), and 2 + 2 = 4 (not always quite true). But most importantly: a meta-skeptic should doubt the claims of supposed “skeptics” and even his/her own certainty.
The real world is much more complex than any of us could appropriately analyze in our lifetimes. Even a simple coin toss is much more complex than people realize.
Fortunately there’s a simple solution to believe as few false things as possible: just say “I’m not sure”.
Excellent article. You have talent ! Keep up the great work.
You say that the 50% answer makes an unwarranted assumption that the coin is a fair coin. That's a bit of a sneaky example and does not do a great job in separating the two types of skeptic. It seems to me that, given the context, it was a warranted assumption. Now, if the context had been one where you are better major money and especially if doing so around people you don't know and who look disreputable, THEN the second level of skepticism becomes sensible and the fairness assumption unwarranted.
But maybe I'm only arguing this because I picked 50% as the answer.